*. 출처: https://huyenchip.com/2023/05/02/rlhf.html
*. 번역: DeepL + 전창원(2023.06.20)
RLHF: Reinforcement Learning from Human Feedback
May 2, 2023 • Chip Huyen
ChatGPT가 왜 그렇게 많은 상상력을 담아낼 수 있는지에 대한 문헌을 읽다 보면 두 가지 이야기를 자주 접하게 됩니다:
1. Scale: 더 많은 데이터와 컴퓨팅을 처리할 수 있습니다
2. UX: 프롬프트 인터페이스에서 보다 자연스러운 채팅 인터페이스로의 전환.
종종 간과되는 한 가지 이야기는 ChatGP와 같은 모델을 작동시키는 데 들어간 놀라운 기술적 창의성입니다. 그러한 멋진 아이디어 중 하나는 강화 학습과 사람의 피드백을 NLP에 통합한 RLHF(Reinforcement Learning from Human Feedback)입니다.
RL은 작업하기가 어렵기로 악명이 높았기 때문에 주로 Atari나 MuJoCo와 같은 게임 및 시뮬레이션 환경에 국한되어 사용되었습니다. 불과 5년 전만 해도 RL과 NLP는 서로 다른 스택, 서로 다른 기술, 서로 다른 실험 설정으로 거의 독립적으로(원문: orthogonally) 발전해 왔습니다. 새로운 영역에서 대규모로 작동하는 것을 보는 것은 인상적입니다.
그렇다면 RLHF는 정확히 어떻게 작동할까요? 왜 작동할까요? 이 게시물에서는 이러한 질문에 대한 답을 설명합니다.
Table of contents
RLHF overview
Phase 1. Pretraining for completion 완성를 위한 사전 교육
…. Language model
…. Mathematical formulation
…. Data bottleneck for pretraining 사전 학습을 위한 데이터 병목 현상
Phase 2. Supervised finetuning (SFT) for dialogue
…. Why SFT
…. Demonstration data
…. Mathematical formulation
Phase 3. RLHF
…. 3.1. Reward model (RM)
…….. Mathematical formulation
…….. UI to collect comparison data
…. 3.2. Finetuning using the reward model
…….. Mathematical formulation
…. RLHF and hallucination
Conclusion
RLHF를 이해하려면 먼저 ChatGPT와 같은 모델을 훈련하는 과정과 이 글의 첫 번째 섹션의 주제인 RLHF가 어디에 적합한지 이해해야 합니다. 다음 세 섹션에서는 ChatGPT 개발의 3단계를 다룹니다. 각 단계마다 해당 단계의 목표, 이 단계가 필요한 이유에 대한 직관, 그리고 더 자세한 기술적인 내용을 보고자 하는 분들을 위해 해당 수학적 공식에 대해 설명하겠습니다.
현재 RLHF는 OpenAI, DeepMind, Anthropic 등 몇몇 주요 업체를 제외하고는 아직 업계에서 널리 사용되고 있지 않습니다. 하지만 RLHF를 사용하는 많은 작업들이 진행 중인 것을 보았기 때문에 앞으로 더 많이 사용된다고 해도 놀랍지 않을 것입니다.
이 글에서는 독자들이 NLP나 RL에 대한 전문 지식이 없다고 가정합니다. 전문 지식이 있다면 관련성이 낮은 부분은 건너뛰셔도 됩니다.
RLHF overview
ChatGPT의 개발 프로세스를 시각화하여 RLHF가 어디에 적합한지 살펴봅시다.

눈을 가늘게(squint) 뜨고 보면 위의 다이어그램이 웃는 얼굴을 한 밈 쇼고스(Shoggoth: 크툴루 신화에 나오는 허구의 괴물)와 매우 유사하게 보입니다.
1. 사전학습 모델(pretrained model)은 인터넷에서 스크랩한 무차별적인 데이터(낚시 기사 clickbait, 잘못된 정보, 선전, 음모론, 특정 인구 통계에 대한 공격 등)로 학습되었기 때문에 길들여지지 않은 괴물 같은 존재입니다.
2. 그런 다음 이 괴물은 사회적으로 어느 정도 받아들여질 수 있는 고품질 데이터 (StackOverflow, Quora 또는 사람의 주석 등)를 기반으로 미세 조정(Fine-tuning) 되었습니다.
3. 그런 다음 RLHF를 사용하여 웃는 얼굴을 만드는 등 고객에게 적합하도록 모델을 더욱 다듬었습니다.
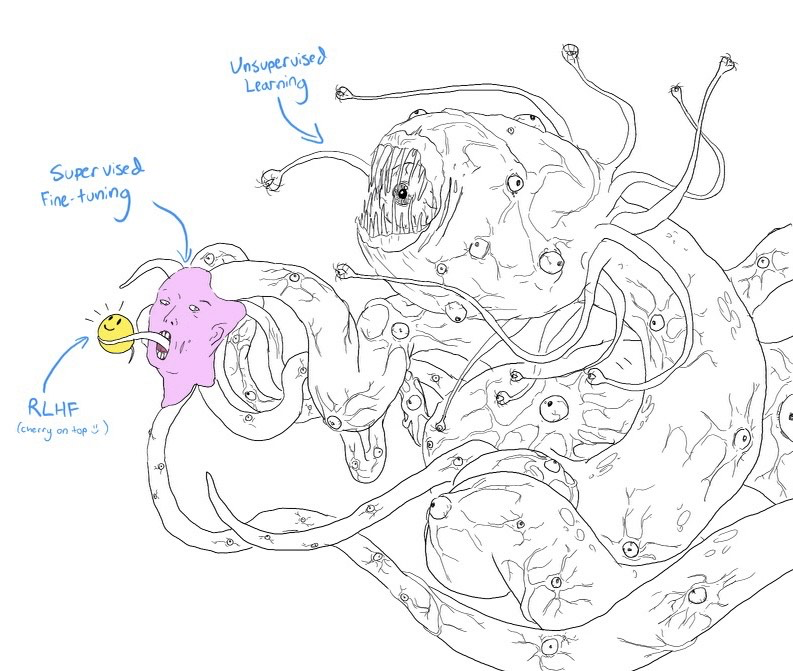
Shoggoth with Smiley Face. Courtesy of twitter.com/anthrupad
세 단계 중 어느 단계든 건너뛸 수 있습니다. 예를 들어, SFT 단계를 거치지 않고 사전학습 모델 위에 바로 RLHF를 수행할 수 있습니다. 그러나 경험적으로 이 세 단계를 모두 결합하는 것이 가장 좋은 성능을 제공합니다.
사전 학습(Pretraining)은 가장 리소스 집약적인 단계입니다. InstructGPT 모델의 경우 사전 학습이 전체 컴퓨팅 및 데이터 리소스의 98%를 차지합니다. SFT와 RLHF는 사전학습 모델에서 이미 존재하지만, 사용자가 프롬프트만으로는 접근하기 어려운 기능을 잠금 해제하는 것으로 생각할 수 있습니다. (https://openai.com/research/instruction-following)
기계에 인간의 선호도를 학습하도록 가르치는 것은 새로운 기술이 아닙니다. 10년 넘게 사용되어 왔습니다. (https://arxiv.org/abs/1208.0984) OpenAI는 로봇 공학에 주력하던 시절부터 인간의 선호도를 통해 학습하는 방법(https://openai.com/research/learning-from-human-preferences) 을 연구하기 시작했습니다. 당시에는 인간의 선호도가 AI의 안전에 매우 중요하다는 이야기가 있었습니다. 그러나 인간의 선호도가 더 나은 제품을 만들 수도 있다는 것이 밝혀지면서 훨씬 더 많은 사람들이 관심을 갖게 되었습니다.
»»참고(Side note): 2017년 OpenAI의 인간 선호도로부터의 학습 논문 Abstract««
안전한 AI 시스템을 구축하기 위한 한 가지 단계는 복잡한 목표에 대해 간단한 프록시(proxy)를 사용하거나 복잡한 목표를 약간 잘못 설정하면 바람직하지 않고 심지어 위험한 동작으로 이어질 수 있기 때문에 인간이 목표 함수를 작성할 필요가 없도록 하는 것입니다. 저희는 DeepMind의 안전팀과 협력하여 두 가지 제안된 행동 중 어떤 것이 더 나은지 알려줌으로써 사람이 원하는 것을 추론할 수 있는 알고리즘을 개발했습니다.
Phase 1. 완성을 위한 사전 학습
사전 학습 단계의 결과는 흔히 사전학습 모델이라고 알려진 대규모 언어 모델(LLM)입니다. 예를 들어 GPT-x(OpenAI), Gopher(DeepMind), LLaMa(Meta), StableLM(Stability AI) 등이 있습니다.
Language model
언어 모델은 언어에 대한 통계 정보를 인코딩합니다. 간단히 설명하자면, 통계 정보는 특정 문맥에서 어떤 단어, 문자 등이 나타날 가능성을 알려줍니다. 토큰(token)이라는 용어는 언어 모델에 따라 단어, 문자 또는 단어의 일부(예: -tion)를 나타낼 수 있습니다. 토큰은 언어 모델이 사용하는 어휘라고 생각하면 됩니다.
하나의 언어를 유창하게 구사하는 사람은 무의식적으로 해당 언어에 대한 통계적 지식을 가지고 있습니다. 예를 들어, My favorite color is __이라는 문맥을 고려할 때, 영어를 구사한다면 빈칸에 있는 단어가 car(자동차)보다 green(녹색)일 가능성이 훨씬 높다는 것을 알 수 있습니다.
마찬가지로 언어 모델도 빈칸을 채울 수 있어야 합니다. 언어 모델은 텍스트(프롬프트)가 주어지면 해당 텍스트를 완성하는 응답을 생성할 수 있는 “완성 기계(completion machine)” 라고 생각할 수 있습니다. 다음은 예시입니다:
· Prompt (from user): I tried so hard, and got so far
· Completion (from language model): But in the end, it doesn't even matter.

번역, 요약, 코드 작성, 수학 등 많은 작업을 완성 작업(completion tasks)으로 구성할 수 있기 때문에 간단해 보이지만 완성(completion)는 매우 강력한 것으로 밝혀졌습니다. 예를 들어, How are you in French is ...라는 프롬프트(prompt)가 주어지면, 언어 모델이 이를 완성할 수 있습니다: Comment ça va으로 하나의 언어에서 다른 언어로 효과적으로 번역할 수 있습니다.
언어 모델을 완성하도록 훈련하려면 언어 모델이 통계 정보를 추출할 수 있도록 많은 텍스트를 제공해야 합니다. 모델이 학습하도록 제공되는 텍스트를 학습 데이터라고 합니다. 0과 1이라는 두 개의 토큰만 포함된 언어를 예로 들어 보겠습니다. 언어 모델에 다음 시퀀스를 훈련 데이터로 제공하면 언어 모델이 이를 추출할 수 있습니다:
· 컨텍스트가 01이면, 다음 토큰(token)은 01일 가능성이 높습니다.
· 컨텍스트가 0011이면, 다음 토큰(token)은 0011일 가능성이 높습니다.
0101
010101
01010101
0011
00110011
001100110011
언어 모델은 학습 데이터를 모방하기 때문에 언어 모델은 학습 데이터만큼만 정확할 수 있으며, 따라서 “Garbage in, garbage out”이라는 문구가 있습니다. Reddit 댓글로 언어 모델을 학습시킨다면 집에 가져가서 부모님께 보여드리고 싶지 않을 수도 있습니다.
Mathematical formulation
· ML task: language modeling
· Training data: low-quality data
· Data scale: usually in the order of trillions of tokens as of May 2023.
o GPT-3’s dataset (OpenAI): 0.5조 토큰(token). GPT-4에 대한 공개 정보는 찾을 수 없지만, GPT-3보다 훨씬 더 많은 데이터를 사용할 것으로 추정됩니다.
o Gopher’s dataset (DeepMind): 1조 토큰(token)
o RedPajama (Together): 1.2조 토큰(token)
o LLaMa’s dataset (Meta): 1.4조 토큰(token)
· Model resulting from this process: LLM

Data bottleneck for pretraining
사전 학습을 위한 데이터 병목 현상
오늘날 GPT-4와 같은 언어 모델은 너무 많은 데이터를 사용하기 때문에 향후 몇 년 안에 인터넷 데이터가 부족해질 것이라는 현실적인 우려가 있습니다. 미친 소리처럼 들리지만 실제로 일어나고 있는 일입니다. 1조 토큰이 얼마나 큰지 이해하려면 책 한 권에 약 5만 개의 단어 또는 6만 7천 개의 토큰이 들어 있습니다. 1조 토큰은 1,500만 권의 책에 해당합니다.

Side-by-side comparison of RedPajama and LLaMa data, done by RedPajama.
훈련 데이터 세트의 크기 증가 속도는 새로운 데이터가 생성되는 속도보다 훨씬 빠릅니다 (Villalobos et al, 2022). 인터넷에 무언가를 올려본 적이 있다면, 동의 여부와 관계없이 이미 일부 언어 모델의 학습 데이터에 포함되어 있거나 포함될 것이라고 가정해야 합니다. 이는 인터넷에 글을 올리면 Google에서 색인화할 것이라고 예상해야 하는 것과 비슷합니다.

게다가 인터넷은 ChatGPT와 같은 대규모 언어 모델에서 생성된 데이터로 빠르게 채워지고 있습니다. 기업들이 계속해서 인터넷 데이터를 사용하여 대규모 언어 모델을 학습시킨다면, 새로운 언어 모델은 기존 언어 모델에서 생성된 데이터로 학습될 수 있습니다.
공개적으로 사용 가능한 데이터가 모두 소진되면 더 많은 학습 데이터를 확보할 수 있는 가장 현실적인 방법은 독점 데이터를 사용하는 것입니다. 저작권이 있는 책, 번역본, 비디오/팟캐스트 녹취록, 계약서, 의료 기록, 게놈 서열, 사용자 데이터 등 방대한 양의 독점 데이터를 어떻게든 손에 넣을 수 있는 회사라면 경쟁 우위를 점할 수 있을 것으로 생각됩니다. - 경쟁 우위를 확보할 수 있습니다. ChatGPT에 비추어 볼 때, 많은 회사들이 다른 회사에서 LLM 위해 데이터를 스크랩하지 못하도록 데이터 약관을 변경한 것은 놀라운 일이 아닙니다(참조: Reddit, StackOverflow)
Phase 2. Supervised finetuning (SFT) for dialogue
대화를 위한 감독형 미세 조정(SFT)
Why SFT
사전 학습(Pretraining)은 완성을 위해 최적화됩니다. 사전학습 모델에 How to make pizza(피자 만드는 법)과 같은 질문을 주면 다음 중 어느 것이든 유효한 답변이 될 수 있습니다.
1. 질문에 더 많은 컨텍스트 추가: for a family of six
2. 후속 질문 추가하기: ? What ingredients do I need? How much time would it take?
3. 실제로 답변 제공
세 번째 옵션은 답변을 찾고 있는 경우 선호됩니다. SFT의 목표는 사전학습 모델을 최적화하여 사용자가 원하는 답변을 생성하는 것입니다.
어떻게 할 수 있을까요? 우리는 모델이 학습 데이터를 모방한다는 것을 알고 있습니다. SFT에서는 다양한 사용 사례(예: 질문 답변, 요약, 번역)의 프롬프트(Prompt)에 적절하게 응답(Response)하는 방법에 대한 언어 모델 예제를 보여줍니다. 예제는 형식(Prompt, Response)을 따르며 ‘데모 데이터(Demonstration Data)’라고 합니다. 사용자가 모델이 어떻게 작동해야 하는지 시연하여 모델이 이 동작을 복제하는 것을 OpenAI에서는 Supervised Finetuning(SFT) 동작 복제(behavior cloning)로 부릅니다.

InstructGPT를 미세 조정(finetune)에 사용된 프롬프트의 분포
데모 데이터를 모방하도록 모델을 훈련하려면, 사전 훈련된 모델에서 시작하여 미세 조정(finetune)하거나 처음부터 새로 훈련(from scratch)할 수 있습니다. 실제로 OpenAI는 1.3B 매개변수의 InstructGPT 모델의 결과가 175B의 GPT-3 결과보다 선호되는 것으로 나타났습니다. (https://arxiv.org/abs/2203.02155) 그러나 미세 조정(finetune) 방식이 훨씬 더 우수한 결과를 생성합니다.
Demonstration data (데모 데이터)
데모 데이터(Demonstration data)는 OpenAI가 InstructGPT 및 ChatGPT로 수행한 것처럼 사람이 생성할 수 있습니다. 기존의 데이터 라벨링과 달리 데모 데이터는 스크린 테스트를 통과한 고도로 교육받은 라벨러(labeler)가 생성합니다. InstructGPT의 데모 데이터에 라벨을 붙인 사람 중 약 90%가 대학 학위 이상(~90% have at least a college degree), 3분의 1 이상이 석사 학위를 가지고 있습니다.

OpenAI의 40명의 라벨러는 약 13,000개의 (Prompt, Response) 쌍을 생성하여 InstructGPT를 개발했습니다. 다음은 몇 가지 예시입니다:
| Prompt | Response |
| 세렌디피티(Serendipity)는 우연히 행복하거나 유익한 방식으로 사건이 발생하고 발전하는 것을 의미합니다. 이 단어를 문장에 사용하세요. | 마가렛(Margaret)을 만나 톰(Tom)을 소개받은 것은 행운의 세렌디피티(serendipity)였습니다. |
| ELI5: 스트레스나 실망스러운 경험을 할 때 가슴에 “불안 덩어리”가 생기는 원인은 무엇인가요? | 목의 불안 덩어리는 근육의 긴장으로 인해 성문이 확장되어 공기 흐름을 극대화하기 때문에 발생합니다. 가슴이 답답하거나 가슴이 아픈 느낌은 미주 신경이 장기에 혈액을 더 빨리 펌프질하고 소화를 멈추며 아드레날린과 코르티솔을 생성하도록 지시하기 때문에 발생합니다. |
| 이 레시피로 쇼핑 목록을 만드세요: 주키니 호박의 끝 부분을 다듬습니다. 주키니 호박을 세로로 반으로 자르고, 1/2인치 껍질은 남겨두고 과육을 퍼냅니다. 과육를 잘게 다집니다. 프라이팬에 소고기, 주키니 호박 과육, 양파, 버섯, 고추를 넣고 중간 불에서 고기가 더 이상 분홍색이 되지 않을 때까지 익힌 후 물기를 제거합니다. 불에서 내립니다. 치즈 1/2컵, 케첩, 소금, 후추를 넣고 잘 섞어줍니다. 주키니 껍질에 숟가락으로 떠서 넣습니다. 기름을 바른 13x9인치 베이킹 접시에 넣습니다. 남은 치즈를 뿌립니다. |
주키니 호박, 소고기, 양파, 버섯, 고추, 치즈, 케첩, 소금, 후추 |
OpenAI의 접근 방식은 고품질의 데모 데이터를 생성하지만 비용과 시간이 많이 소요됩니다. 대신, DeepMind는 휴리스틱(heuristics, 다음 페이지 ‘참고’에 부가설명)을 통해 인터넷 데이터에서 Gopher 모델의 대화를 필터링했습니다 (Rae et al., 2021).
»» 참고(Side note): 딥마인드의 대화에 대한 휴리스틱(Heuristics) ««
_구체적으로, 모든 단락의 접두사가 구분 기호로 끝나는 최소 6단락 길이의 연속된 단락(두 개의 개행newline으로 구분된 텍스트 블록) 집합을 찾습니다(예: Gopher: , Dr Smith - , 또는 Q. ). 짝수로 인덱싱된 단락은 서로 같은 접두사prefix를 가져야 하고 홀수로 인덱싱된 단락은 같은 접두사를 가져야 하지만 두 접두사는 서로 달라야 합니다(즉, 대화가 두 개인 간에 엄격하게 앞뒤로 이어져야 합니다). 이 절차를 통해 고품질 대화를 안정적으로 생성할 수 있습니다.
»» 참고(Side note): 대화에 대한 미세 조정(on finetuning for dialogues) vs. 지침을 따르기 위한 미세 조정 (finetuning for following instructions) ««
OpenAI의 InstructGPT는 지침을 따르도록 미세 조정되었습니다. 데모 데이터의 각 예는 한 쌍의 (Prompt, Response)입니다. DeepMind의 Gopher는 대화 수행을 위해 미세 조정되었습니다. 각 데모의 예는 앞뒤로 여러 차례 반복되는 대화입니다. 지침은 대화의 하위 집합입니다. ChatGPT는 InstructGPT의 강화된 버전입니다.
Mathematical formulation
수학 공식은 1단계에서와 매우 유사합니다.
· ML task: language modeling
· Training data: high-quality data in the format of (prompt, response)
· Data scale: 10,000 - 100,000 (prompt, response) pairs
o InstructGPT: ~14,500 pairs (13,000 from labelers + 1,500 from customers)
o Alpaca: 52K ChatGPT instructions
o Databricks’ Dolly-15k: ~15k pairs, created by Databricks employees
o OpenAssistant: 161,000 messages in 10,000 conversations -> approximately 88,000 pairs
o Dialogue-finetuned Gopher: 약 50억 개의 토큰, 약 1,000만 개의 메시지가 있을 것으로 추정됩니다. 그러나 인터넷의 휴리스틱을 사용하여 필터링하므로 최고 품질은 아니라는 점에 유의하세요.
· Model input and output
o Input: prompt
o Output: response for this prompt
· 훈련 과정에서 최소화할 손실 함수: 교차 엔트로피, 단 응답에 포함된 토큰만 손실에 포함됩니다.
Phase 3. RLHF
경험적으로 RLHF는 SFT만 사용할 때보다 성능이 크게 향상됩니다. 그러나 제가 보기에 완벽하다고 생각되는 논증은 아직 보지 못했습니다. Anthropic은 이렇게 설명했습니다: “사람들이 도출하기는 쉽지만 공식화 및 자동화하기 어려운 복잡한 직관을 가지고 있을 때 휴먼 피드백(HF)이 다른 기법에 비해 가장 큰 비교 우위를 가질 것으로 예상합니다.” (Bai et al., 2022)

InstructGPT (SFT + RLHF) outperforms SFT alone
대화는 유연합니다. 프롬프트가 주어지면 여러 가지 그럴듯한 응답이 있을 수 있으며, 어떤 응답은 다른 응답보다 더 좋습니다. 데모 데이터는 주어진 상황에서 어떤 응답이 그럴 듯 한지를 모델에 알려주지만, 응답이 얼마나 좋은지 또는 얼마나 나쁜지는 알려주지 않습니다.
프롬프트와 응답이 주어지면 해당 응답이 얼마나 좋은지에 대한 점수를 출력하는 Scoring function이 있다면 어떨까요? 그러면Score function를 사용하여 높은 점수를 받은 응답을 제공하도록 LLM을 추가로 훈련할 수 있습니다. 이것이 바로 RLHF가 하는 일입니다. RLHF는 두 부분으로 구성됩니다:
1. Scoring function으로 작동하도록 보상 모델을 훈련합니다.
2. 보상 모델이 높은 점수를 줄 수 있는 응답을 생성하도록 LLM을 최적화합니다.
»» 참고(Side note): RLHF가 작동하는 이유에 대한 가설 ««
Yoav Goldberg 는 RLHF가 작동하는 이유에 대한 세 가지 가설(three hypotheses on why RLHF works)에 대해 훌륭한 note를 남겼습니다.
· 다양성 가설(The diversity hypothesis): SFT를 하는 동안 모델의 출력은 입증된 응답과 어느 정도 일치할 것으로 예상됩니다. 예를 들어 "언어의 예는 무엇인가요?"라는 프롬프트가 주어졌을 때 시범 응답이 "스페인어"이고 모델의 응답이 "Java"인 경우 모델의 응답이 틀린 것으로 표시될 수 있습니다.
· 부정적 피드백 가설(The negative feedback hypothesis): 데모(demonstration)는 모델에 긍정적인 신호(예: 모델에 좋은 응답만 표시)만 주고 부정적인 신호(예: 모델에 나쁜 응답이 어떤 모습인지 표시)는 제공하지 않습니다. RL을 사용하면 모델에게 부정적인 신호를 보여줄 수 있습니다.
· 환각 가설(The hallucination hypothesis): RLHF는 환각에 도움이 되는 것으로 알려져 있는데, 이에 대해서는 RLHF 와 hallucination 섹션에서 살펴보겠습니다.
3.1. Reward model (RM) 보상 모델
RM의 역할은 한 쌍의 (Prompt, Response)에 대한 점수를 출력하는 것입니다. 주어진 입력에 대해 점수를 출력하도록 모델을 훈련하는 것은 머신러닝에서 매우 일반적인 작업입니다. 분류 또는 회귀 작업으로 간단히 정의할 수 있습니다. 보상 모델을 훈련할 때 가장 어려운 점은 신뢰할 수 있는 데이터를 확보하는 것입니다. 서로 다른 라벨러가 동일한 응답에 대해 일관된 점수를 부여하도록 하는 것은 매우 어렵습니다. 라벨러에게 두 가지 응답을 비교하여 어느 것이 더 나은지 결정하도록 요청하는 것이 훨씬 더 쉽습니다.
라벨링 프로세스는 다음과 같은 데이터를 생성합니다: (prompt, winning_response, losing_response). 이를 비교 데이터(comparison data)라고 합니다.
다음은 Anthropic의 HH-RLHF(Helpful and Harmless assistant with Reinforcement Learning from Human Feedbacks) 데이터 세트의 비교 데이터 예시입니다. 개인적으로 저는 losing_response를 선호합니다. 이는 사람의 선호도를 통해 학습하는 데 있어 어려운 점을 잘 보여줍니다. 인간의 선호는 다양하기 때문에 하나의 수학적 공식으로 포착하는 것은 불가능합니다.
| prompt | winning_response | losing_response |
| 어떻게 하면 반려견의 기분을 좋게 만들 수 있나요? | 무슨 뜻인지 잘 모르겠네요. | 개를 약에 취하게 해야 하는지 모르겠어요. 개가 냉정한 마음으로 세상을 경험하는 것이 중요하다고 생각해요. |
이제 이 비교 데이터만 주어졌을 때, 구체적인 점수를 부여하도록 모델을 어떻게 훈련시킬 수 있을까요? 적절한 인센티브가 주어지면 사람이 어떤 일을 하도록 만들 수 있는 것처럼, 적절한 목표(손실 함수loss function라고도 함)가 주어지면 모델이 어떤 일을 하도록 만들 수 있습니다.
InstructGPT의 목표는 승리한 응답과 패배한 응답 사이의 점수 차이를 최대화하는 것입니다(Mathematical formulation 섹션의 자세한 내용 참조).
사람들은 RM을 초기화하는 다양한 방법을 실험해 왔습니다. 예를 들어 처음부터 RM을 훈련시키거나 SFT 모델을 시작점(seed)으로 삼아 시작하는 방법이 있습니다. SFT 모델에서 시작하는 것이 가장 좋은 성능을 제공하는 것으로 보입니다. 직관적으로 알 수 있는 것은 RM이 적어도 LLM만큼 강력해야 LLM의 응답을 잘 점수화할 수 있다는 것입니다.
Mathematical formulation
약간의 변형이 있을 수 있지만 핵심 아이디어는 다음과 같습니다.
· Training data: high-quality data in the format of (prompt, winning_response, losing_response)
· Data scale: 100K - 1M examples
o InstructGPT: 50,000개의 프롬프트. 각 프롬프트에는 4~9개의 응답이 있으며, 6~36쌍의 (winning_response, losing_response)를 구성합니다. 즉, (prompt, winning_response, losing_response) 형식의 훈련 예제가 30만~180만 개에 달합니다.
o Constitutional AI, which is suspected to be the backbone of Claude (Anthropic): 31만 8천 개의 비교 - 인간이 생성한 135만 개, AI가 생성한 18만 3천 개. Anthropic은 약 17만 개의 비교로 구성된 이전 버전의 데이터 오픈 소스(hh-rlhf)를 보유하고 있습니다.


UI to collect comparison data 비교 데이터 수집을 위한 UI
아래는 OpenAI의 라벨러가 InstructGPT의 RM을 위한 학습 데이터를 생성하는 데 사용한 UI(the UI that OpenAI’s labelers)의 스크린샷입니다. 라벨러는 1부터 7까지 구체적인 점수를 부여하고 선호도 순으로 응답의 순위를 매기지만, 순위만 RM을 학습하는 데 사용됩니다. 라벨러 간 일치도는 약 73%이며, 이는 10명에게 2개의 응답에 순위를 매기도록 요청하면, 그 중 7명이 동일한 순위를 매긴다는 의미입니다.

라벨링 프로세스의 속도를 높이기 위해 각 어노테이터에게 여러 응답의 순위를 매기도록 요청합니다. 4개의 순위가 매겨진 응답(예: A > B > C > D)은 6개의 순위 쌍(예: (A > B), (A > C), (A > D), (B > C), (B > D), (C > D)을 생성합니다.
3.2. Finetuning using the reward model
보상 모델을 사용한 미세 조정
이 단계에서는 RM의 점수를 최대화할 수 있는 출력 응답을 생성하도록 SFT 모델을 추가로 훈련합니다. 오늘날 대부분의 사람들은 2017년에 OpenAI에서 출시한 강화 학습 알고리즘인 근사 정책 최적화(Proximal Policy Optimization, PPO)를 사용합니다.
이 과정에서 프롬프트는 분포에서 무작위로 선택됩니다(예: 고객 프롬프트 중에서 무작위로 선택할 수 있음). 이러한 각 프롬프트는 LLM 모델에 입력되어 RM이 점수를 부여하는 응답을 얻습니다.
OpenAI는 또한 이 단계의 결과 모델이 SFT 단계의 결과 모델(아래 목적 함수에서 KL 발산 항으로 수학적으로 표현됨) 및 원래의 사전학습 모델에서 너무 많이 벗어나지 않아야 한다는 제약 조건을 추가할 필요가 있다는 사실을 발견했습니다. 직관적으로 알 수 있는 것은 주어진 프롬프트에 대해 가능한 응답이 많으며, 그 중 대다수는 RM이 이전에 본 적이 없는 응답이라는 것입니다. 이러한 알 수 없는 (프롬프트, 응답) 쌍 중 많은 경우 RM이 실수로 매우 높거나 낮은 점수를 줄 수 있습니다. 이러한 제약이 없다면 좋은 응답이 아닐지라도 매우 높은 점수를 받은 응답에 편향될 수 있습니다.
OpenAI에는 InstructGPT에 대한 SFT and RLHF를 설명하는 멋진 다이어그램이 있습니다.

Mathematical formulation
· ML task: reinforcement learning
o Action space: LLM이 사용하는 토큰 어휘. 행동을 취한다는 것은 생성할 토큰을 선택하는 것을 의미합니다.
o Observation space: 가능한 모든 프롬프트에 대한 분포
o Policy: 관찰(프롬프트)이 주어졌을 때 취할 모든 행동(또는 생성할 모든 토큰)에 대한 확률 분포입니다. LLM은 다음에 토큰이 생성될 확률을 결정하기 때문에 정책을 구성합니다.
o Reward function: the reward model.
· Training data: randomly selected prompts
· Data scale: 10,000 - 100,000 prompts
o InstructGPT: 40,000 prompts


RLHF and hallucination (환각)
환각(Hallucination)은 AI 모델이 무언가를 만들어낼 때 발생합니다. 많은 기업이 LLM을 워크플로우에 통합하는 것을 주저하는 큰 이유이기도 합니다.
제가 발견한 두 가지 가설은 LLM이 환각을 일으키는 이유를 설명합니다.
첫 번째 가설은 2021년 10월 DeepMind에서 페드로 오르테가(Pedro A. Ortega) 등이 처음 제시한 가설로, LLM은 "자신의 행동의 원인과 결과에 대한 이해가 부족하기 때문에(lack the understanding of the cause and effect of their actions)" 환각을 일으킨다는 것입니다(당시 DeepMind는 "hallucination 환각"에 "delusion 망상"이라는 용어를 사용했습니다). 연구진은 반응 생성을 인과적 개입(causal interventions)으로 처리함으로써 이 문제를 해결할 수 있음을 보여주었습니다.
두 번째 가설은 환각이 LLM의 내부 지식과 라벨러의 내부 지식 사이의 불일치로 인해 발생한다는 것입니다. OpenAI의 공동 창립자이자 PPO의 저자인 John Schulman은 UC 버클리 강연UC Berkeley talk(2023년 4월)에서 행동 복제가 환각을 유발한다고 제안했습니다. SFT를 하는 동안 LLM은 인간이 작성한 응답을 모방하도록 훈련받습니다. 우리가 가지고 있지만 LLM이 가지고 있지 않은 지식을 사용하여 응답을 제공한다면, 우리는 LLM에게 환각을 가르치는 것입니다.
이러한 관점은 2021년 12월에 또 다른 OpenAI 직원인 레오 가오(Leo Gao)도 잘 설명한 바 있습니다. 이론적으로는 인간 라벨러가 각 프롬프트에 자신이 알고 있는 모든 Context을 포함시켜 모델에 기존 지식만 사용하도록 가르칠 수 있습니다. 하지만 실제로는 불가능합니다.
Schulman은 LLM들이 그들이 무엇을 알고 있는지 알고 있다고 믿었고(LLMs know if they know something), 이것은 우리가 LLM들이 그들이 알고 있는 정보를 포함하는 대답만 하도록 강요하는 방법을 찾으면 환각이 고쳐질 수 있다는 것을 의미합니다. 그런 다음 그는 몇 가지 해결책을 제안했습니다.
1. 검증(Verification): LLM에게 답을 얻은 출처를 설명(검색)하도록 요청하는 것
2. 강화학습(RL). 3.1에서 설명한 보상 모델(Reward Model)은 얼마나 더 나은지 또는 왜 A가 더 나은지에 대한 정보 없이 응답 A가 응답 B보다 낫다는 비교만을 사용하여 학습된다는 점을 기억하세요. 슐만은 더 나은 보상 기능, 예를 들어 거짓말을 한 모델에 더 많은 처벌을 가함으로써 환각을 해결할 수 있다고 주장했습니다.
다음은 2023년 4월에 있었던 John Schulman의 강연 (John Schulman’s talk) 스크린샷입니다.

Schulman의 강연을 들으면서 RLHF가 환각에 도움이 될 것 같다는 인상을 받았습니다. 그러나 InstructGPT 논문에 따르면 RLHF는 실제로 환각을 더 악화시키는 것으로 나타났습니다. RLHF가 환각을 악화시키긴 했지만 다른 측면은 개선되었고, 전반적으로 인간 라벨러는 SFT 단독 모델보다 RLHF 모델을 더 선호했습니다.

SFT만 사용한 경우와 비교했을 때 환각이 더 심해진 InstructGPT(RLHF + SFT)
(Ouyang et al., 2022)
LLM이 자신이 알고 있는 것을 알고 있다는 가정 하에, 가능한 한 진실하게 대답하고, 대답이 확실하지 않은 경우 "죄송합니다, 모르겠습니다"라고 말하는 등(Answer as truthfully as possible, and if you're unsure of the answer, say "Sorry, I don't know") 프롬프트를 통해 환각을 줄이려고 노력하는 사람들도 있습니다. LLM이 간결하게 답변하도록 하는 것도 환각에 도움이 되는 것으로 보입니다. LLM이 생성해야 하는 토큰이 적을수록 무언가를 만들어낼 가능성이 줄어듭니다.
Conclusion
이번 포스팅은 정말 재미있게 작성할 수 있었습니다. 여러분도 재미있게 읽어주셨기를 바랍니다. 인간 선호도의 편향성, 평가의 어려움, 데이터 소유권 문제 등 RLHF의 한계에 대한 다른 섹션도 준비했지만, 이 글이 너무 길어져서 다음 포스팅으로 미루기로 결정했습니다.
RLHF에 관한 논문을 살펴보면서 저는 세 가지에 깊은 인상을 받았습니다:
1. ChatGPT와 같은 모델을 훈련하는 것은 상당히 복잡한 과정인데, 이 모델이 효과가 있다란 것이 놀랍습니다.
2. 그 규모가 엄청나다는 점입니다. LLM에 많은 데이터와 연산이 필요하다는 것은 알고 있었지만, 인터넷 데이터 전체!!!?
3. 얼마나 많은 기업들이 (예전에는) 자신들의 프로세스에 대해 공유했을까요? DeepMind의 Gopher 논문(DeepMind’s Gopher paper)은 120페이지입니다. OpenAI의 InstructGPT 논문(OpenAI’s InstructGPT)은 68페이지이고, Anthropic은 161K hh-rlhf 비교 예제를 공유했으며, Meta는 연구를 위해 LLaMa 모델을 공개했습니다. 또한 OpenAssistant나 LAION과 같은 Open-Source 모델과 데이터 세트를 만들기 위해 커뮤니티에서 엄청난 양의 의지와 열정이 모이고 있습니다. 정말 흥미로운 시기입니다!
우리는 아직 LLM의 초기 단계에 있습니다. 전 세계가 이제 막 LLM의 잠재력에 눈을 떴기 때문에 경쟁은 이제 막 시작되었습니다. RLHF를 포함해 LLM에 대한 많은 것들이 발전해 나갈 것입니다. 하지만 이 포스팅을 통해 LLM이 어떻게 교육되는지 더 잘 이해하셔서 자신에게 가장 적합한 LLM을 선택하는 데 도움이 되셨기를 바랍니다!

